Abstract
We present SAM4D, a multi-modal and temporal foundation model designed for promptable segmentation across camera and LiDAR streams. Unified Multi-modal Positional Encoding (UMPE) is introduced to align camera and LiDAR features in a shared 3D space, enabling seamless cross-modal prompting and interaction. Additionally, we propose Motion-aware Cross-modal Memory Attention (MCMA), which leverages ego-motion compensation to enhance temporal consistency and long-horizon feature retrieval, ensuring robust segmentation across dynamically changing autonomous driving scenes. To avoid annotation bottlenecks, we develop a multi-modal automated data engine that synergizes VFM-driven video masklets, spatiotemporal 4D reconstruction, and cross-modal masklet fusion. This framework generates camera-LiDAR aligned pseudo-labels at a speed orders of magnitude faster than human annotation while preserving VFM-derived semantic fidelity in point cloud representations. We conduct extensive experiments on the constructed Waymo-4DSeg, which demonstrate the powerful cross-modal segmentation ability and great potential in data annotation of proposed SAM4D.
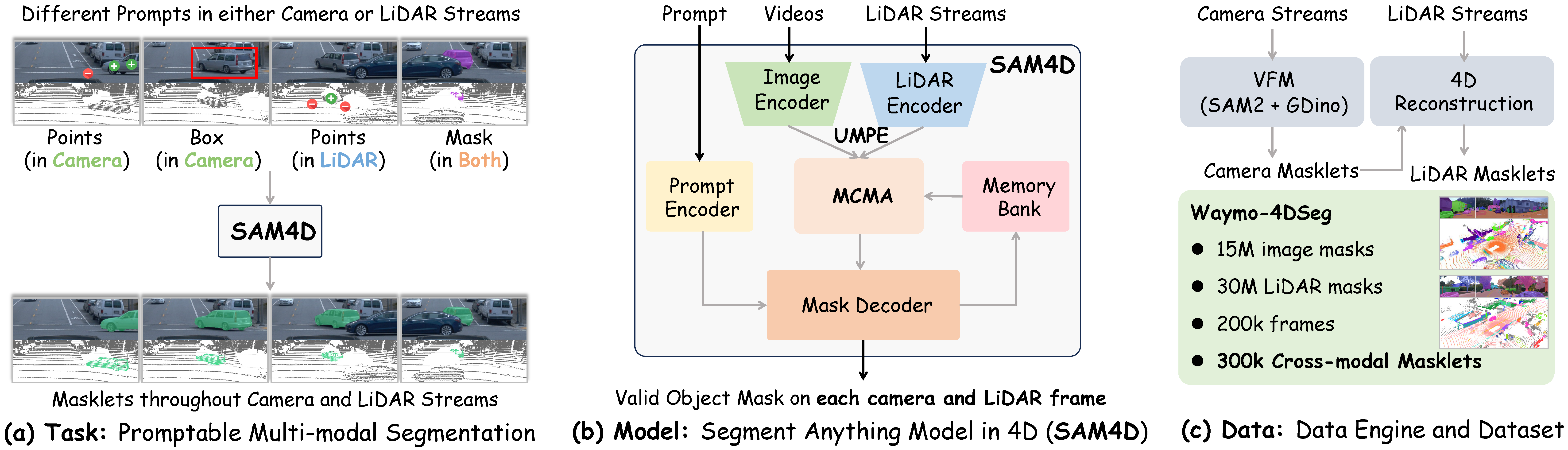
Task: Promptable Multi-modal Segmentation
The Promptable Multimodal Segmentation (PMS) task is designed to enable interactive, cross-modal, and temporal segmentation across both camera and LiDAR streams. Unlike traditional segmentation tasks that rely on a single modality or frame-by-frame processing, PMS allows prompts in either 2D (images) or 3D (LiDAR point clouds) to guide segmentation across the entire sequence.
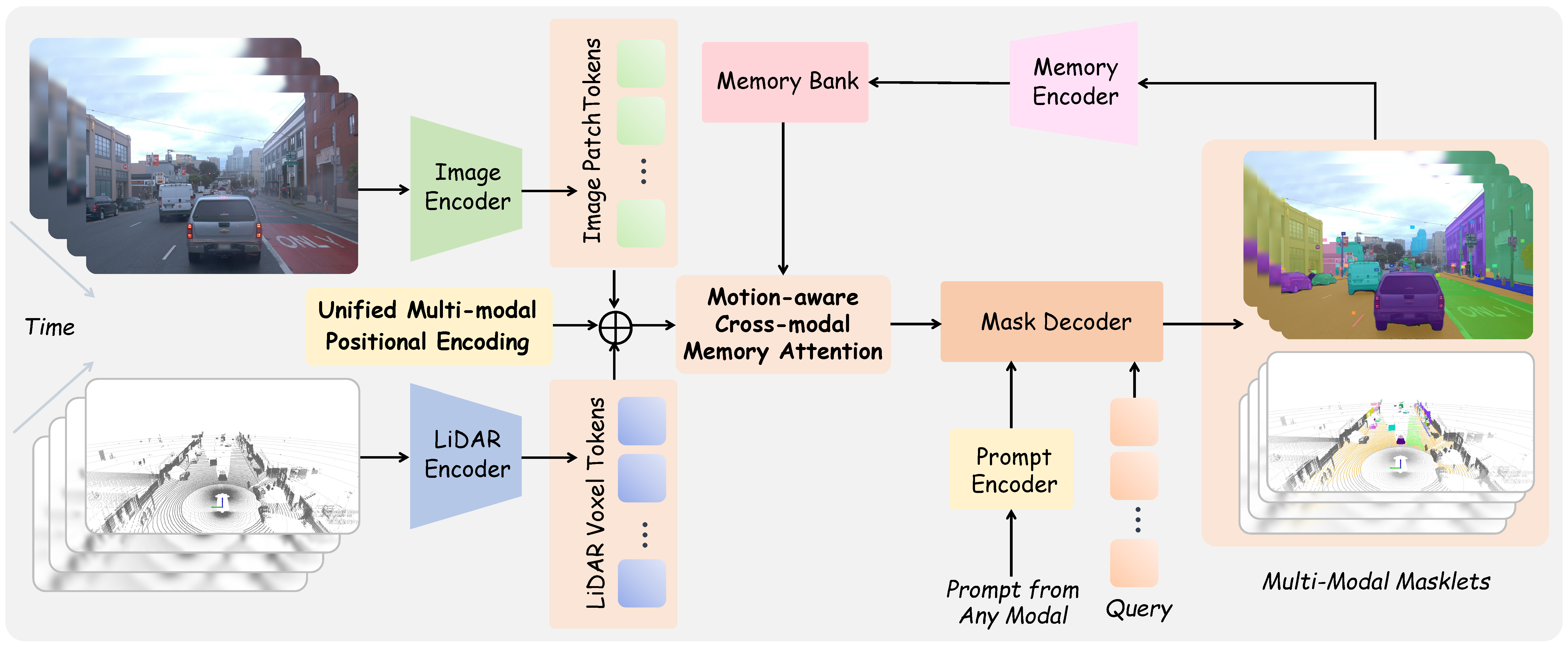
Model: Segment Anything Model in 4D
Overview of the Segment Anything Model in 4D (SAM4D) workflow. The image and LiDAR encoders generate modality-specific embeddings, which are aligned through the proposed Unified Multi-modal Positional Encoding. The Motion-aware Cross-modal Memory Attention then processes multi-modal and temporal features, incorporating ego-motion for improved feature interaction. Finally, the updated image and LiDAR features are queried efficiently by mask decoder with diverse input prompts from various modalities.
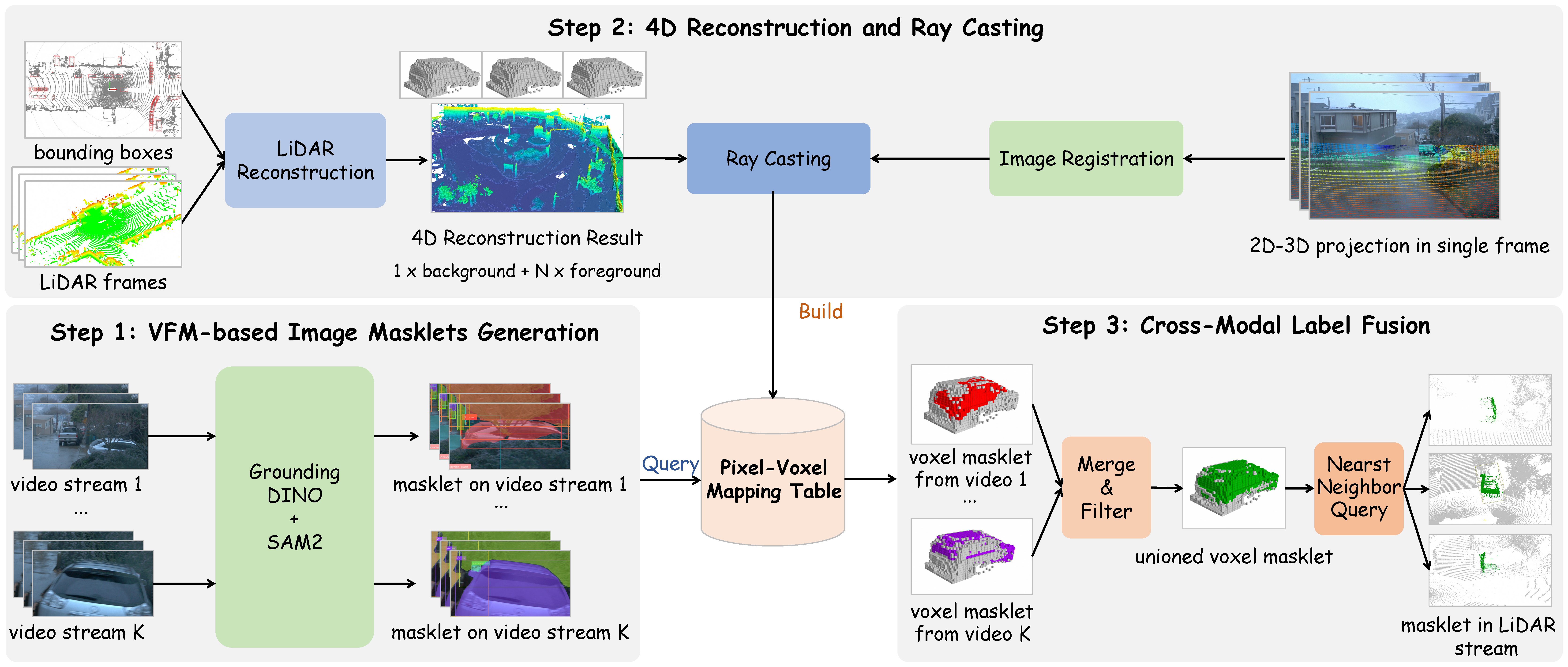
Data: Data Engine and Dataset
Overview of our data engine, which is composed of three steps to construct high-quality pseudo labels.
Qualitative Results
SAM4D demonstrates strong performance across diverse autonomous driving scenarios. Please refer to our paper for detailed quantitative results.
BibTeX
@inproceedings{xu2025sam4d,
title = {SAM4D: Segment Anything in Camera and LiDAR Streams},
author = {Xu, Jianyun and Wang, Song and Ni, Ziqian and Hu, Chunyong and Yang, Sheng and Zhu, Jianke and Li, Qiang},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2025},
}